Architecture¶
A one-screen map of how the pieces fit together.
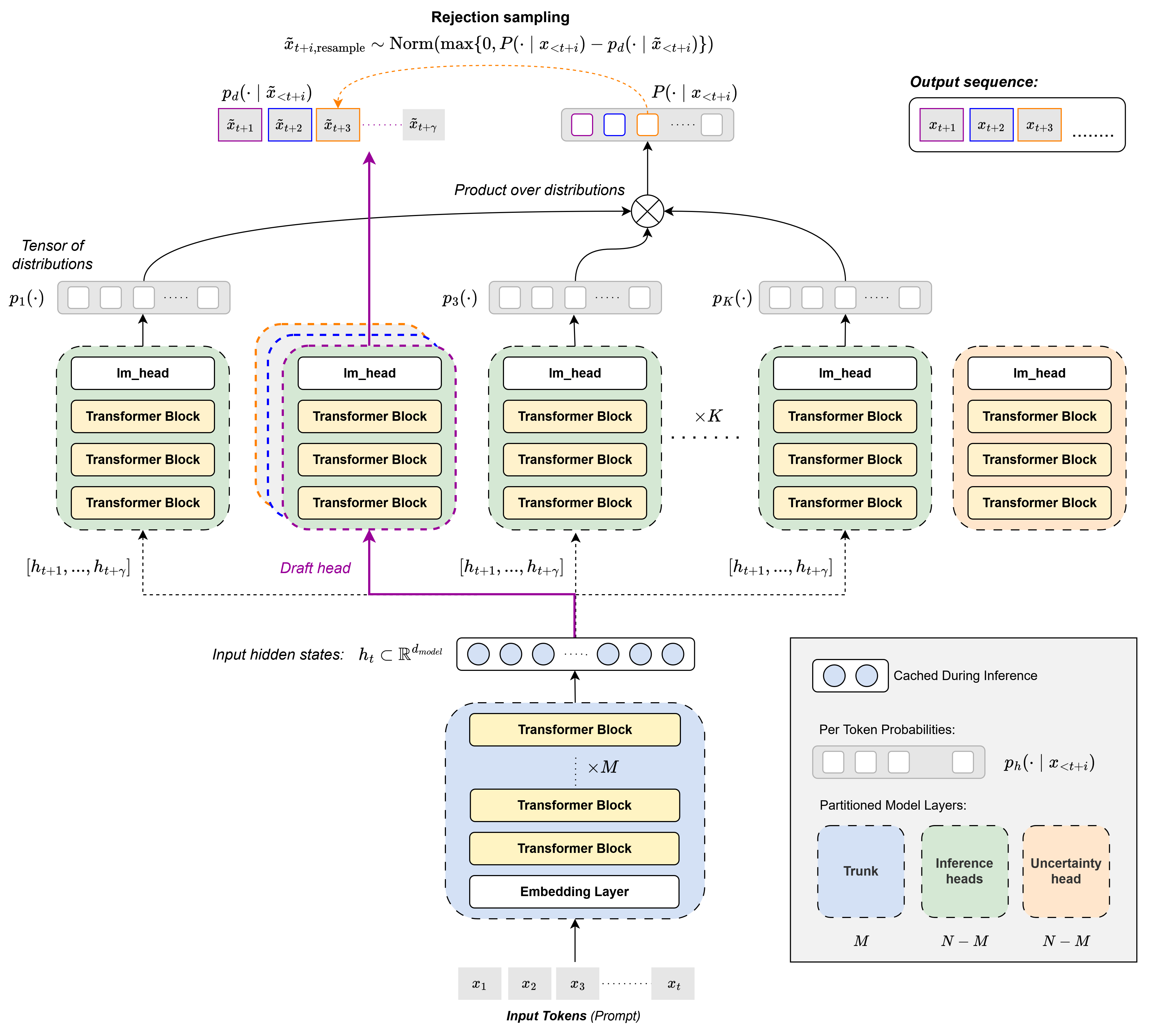
OhLMo with PoE Speculative Verification. A shared trunk feeds K parallel LoRA-tuned heads (nine inference heads and one dedicated uncertainty head), with a draft head proposing tokens that the remaining heads verify as a Product-of-Experts.
Layer by layer¶
olmo_tap/ is the model-side core. hydra.py defines the HydraTransformer, a shared OLMo-2-7B trunk with K parallel LoRA-tuned heads. inference/poe.py composes the heads at decode time via Product-of-Experts Speculative Verification, where a draft head proposes tokens and the remaining heads verify them as a PoE jury. experiments/ holds the three post-training pipelines (security on disjoint MedMCQA shards, KL-based robustness against AmpleGCG suffixes, and a per-answer uncertainty head with residual-stream injection). benchmarks/ and final_evals/ reproduce the decode-throughput and accuracy/calibration numbers from the report. LoRA adapter shards live in weights/ as Git LFS objects.
kernel_entropy/ measures semantic uncertainty over free-text generations using Kernel Language Entropy (Nikitin et al. 2024). It samples N responses from the Hydra+PoE generator, scores pairwise entailment with a ModernBERT NLI head, builds a similarity kernel, and returns a scalar Von Neumann entropy. The same NLI scorer is reused inside app/backend/ for per-claim confidence (single-sample SelfCheckGPT-NLI).
app/ is the user-facing surface. The backend is a FastAPI app deployed on Modal with managed GPUs; it serves Hydra+PoE inference, runs claim decomposition, and assembles the response payload with the three trust signals. The frontend is a React+Vite SPA on Cloudflare Pages that targets whichever backend URL VITE_API_BASE points at, so frontend-only contributors do not need a local GPU.
Trust signals¶
Uncertainty is split by query type. For MCQs it comes from the dedicated Hydra uncertainty head, trained against MCQ correctness with residual-stream injection from a frozen LLM head. For free-text answers it comes from KLE over resampled generations.
Security is delivered by the disjoint-shard post-train across the nine LLM heads. PoE Speculative Verification at decode time turns this into a per-token one-honest-head guarantee, and the verifier ensemble’s per-token predictive entropy drives an optional uncertainty heatmap in the UI.
Robustness is delivered by a KL-based post-train against adversarial suffixes generated by AmpleGCG, plus a runtime probe that re-scores the response under a precomputed attack bank using the same ModernBERT NLI model.
Deployment topology¶
Local:
olmo_tapandkernel_entropyrun viapixi run -e cuda .... Weights live in$OLMO_WEIGHTS_DIR, set in.env.Hosted backend:
app/backend/modal_app.pybuilds its image from the samepixi install -e cuda --lockedused locally, so Modal and dev share one source of truth for dependencies. Thetap-olmo-weightsModal Volume holds the OLMo snapshot and the ModernBERT cache.Hosted frontend: Cloudflare Pages builds
app/frontend/and serves the demo at tap-al9.pages.dev.
Where to look next¶
olmo_tap package — package map for the model core.
Kernel entropy — KLE pipeline usage.
Application — application stack and pipeline.
API reference — auto-generated API reference.